KDL BLOG
こんにちは、Data Intelligence チームの福岡です。今回はちょっとニッチな記事を・・ということで、「LLMを使って文献目録の作成を楽にできないか?」を検証します。
背景と目的
文献目録とは?
文献目録とは、特定のテーマに関する文献を網羅的に収集・整理し一覧化したものです。
具体的には、こんな目録が考えられます。
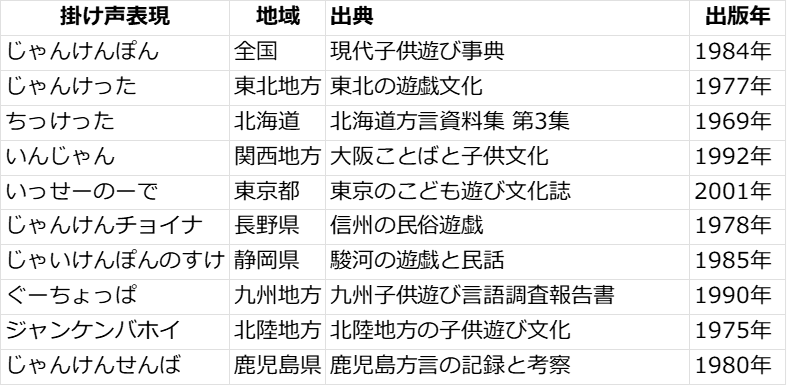
「日本に存在したじゃんけんの掛け声の一覧」ならこんな感じ:
「兵庫・大阪で記録のある生き物目録」ならこんな感じ:

こうした目録は学術的に非常に有用であり、広く活用されています。例えば前者は日本語表現の変遷研究に、後者は地域の生物保全活動に貢献します。 そのため、自然史博物館や大学をはじめとする研究機関では文献目録の作成が重要な業務になっています。 (上記の目録はどちらも全くの架空のデータで、説明のためかなり簡易化しています。「ふーん、文献目録というものがあると人間社会に有用で、それを作成している人がいるんだな」くらいに捉えていただければOKです。)
筆者は趣味でこうした目録を読むのですが、「作成はものすごい大変なハズ・・効率化できないか?」と考えた結果、LLM(Large Language Model;大規模言語モデル)の使用を思いついたので以下のように検証してみました!
文献目録の作成に必要なステップ
目録の作成には、ざっくり以下の3ステップが必要です:
① テーマに該当する文献を過不足なく収集
② 各文献から該当する情報を抜き出す
③ 情報の正確性をチェックする
①、③はそのテーマの専門知識が必要であり、AI等による代替は難しいので今回は取り扱いません。
ここで、ステップ②の「該当する情報を抜き出す」作業を考えると、ここは人間が元の文献とにらめっこしながら手入力(もしくはコピペ)することになり、非常に面倒です。
「この面倒を自動化して、人間は専門性が必要な営みだけ専念するようにできないか?」が本連載の目的です。
方法(概要)
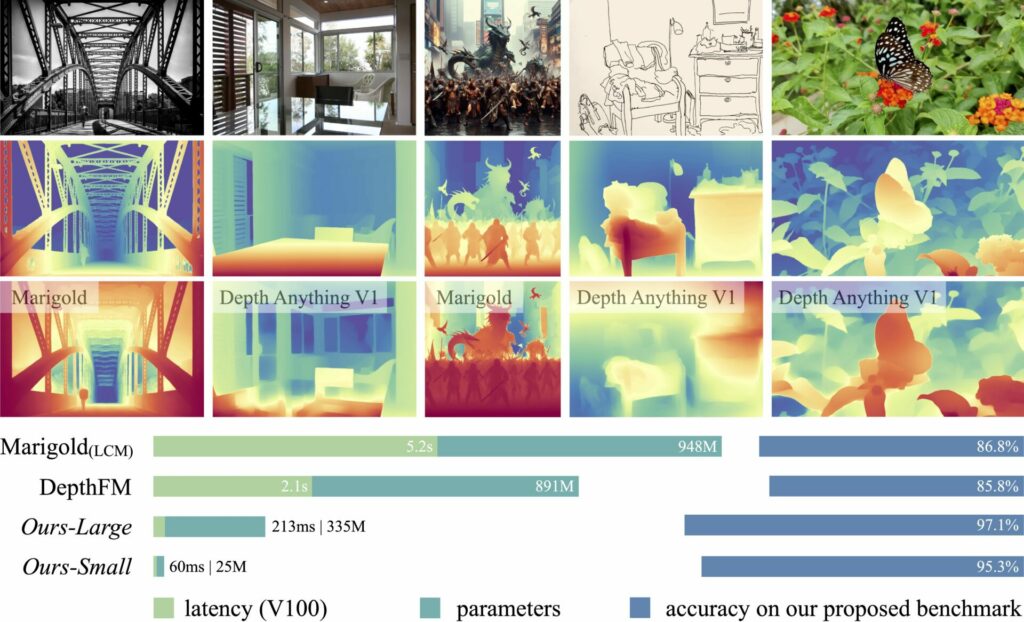
例として「兵庫・大阪で記録のある生き物」をテーマに、以下のステップでLLMによる抽出処理を行ってみます。
- テーマに該当する文献を用意
- Markdown形式に変換
- LLMで情報を抽出(←本記事のキーとなる工程)
- 抽出結果を表形式に整形
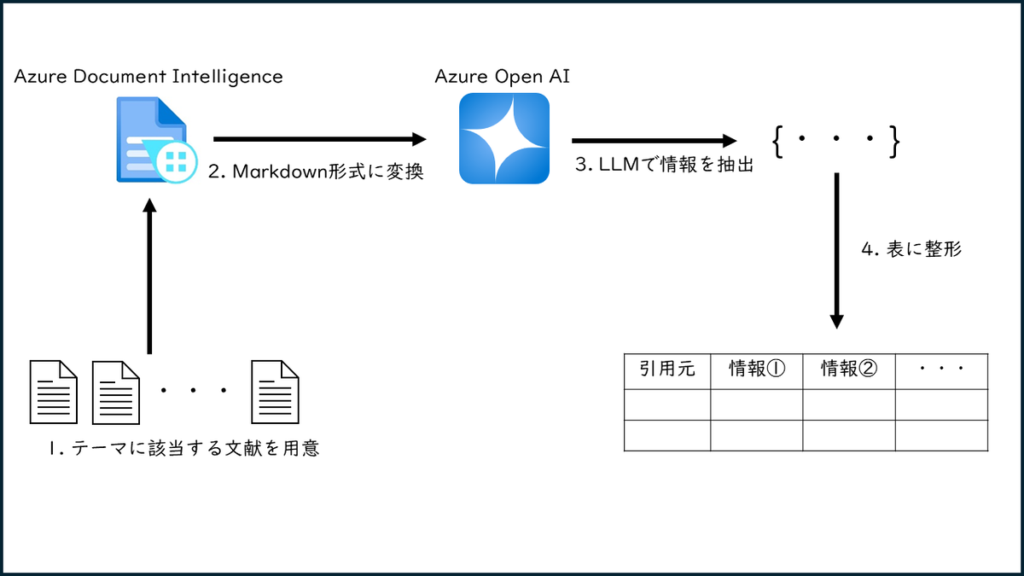
python環境構築はpyenv+poetryで行っています。なお、長くなるので環境構築の細かなやり方やAzureの各種サービスの使用方法は省略します。
順に解説します。
(つづきは、ブログ「神戸のデータ活用塾!KDL Data Blog」へ)