KDL BLOG
Depth Anythingでzero-shot単眼深度推定 ~解説編~
こんにちは!データインテリジェンスチームの吉田です。
今回は、TikTokと複数の大学が共同で開発した最新の単眼深度推定モデル「Depth Anything*1」について詳しく紹介します。
*1:Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data
本記事は連載記事です。解説編と実践編の二部構成となっています!解説編ではDepth Anythingの論文についてちょっとした解説を行いたいと思います。論文の内容よりもまず動かしてみたい!という方は、この記事を飛ばして次回の実践編に向かっても構いません!
要約
- Depth Anythingとは、多様なラベル付きおよびラベルなしデータセットを活用し、Zero-shotで動作可能な単眼深度推定モデル
- ラベルなしデータの効率的な学習と、事前学習したセマンティックセグメンテーション用の情報を保持することで汎化・高精度化を達成
- 単眼深度推定だけでなく、セマンティックセグメンテーションでも高精度化を達成
そもそも単眼深度推定とは?
単眼深度推定とは、単一のカメラ画像からシーンの深度情報(距離情報)を推測する技術です。通常、深度情報を得るためにはステレオカメラやLiDERなどの専用のセンサーが必要とされますが、単眼深度推定ではその名の通り、一つのカメラだけでこの情報を取得することを目指します。

弊社オフィスの一角を深度推定してみた結果がこちらになります。カメラからの距離が近いほど明るく、遠いほど暗くなっていることがわかります。
単眼深度推定は、さまざまな分野で応用が可能です。例えば、拡張現実(AR)の分野では、仮想オブジェクトが現実世界の物体に遮蔽されて見えなくなる効果を実現するときに利用されています。また、画像生成の分野では、深度情報を利用することで、物体の位置関係を保ったまま画像変換を行うときに利用されています。
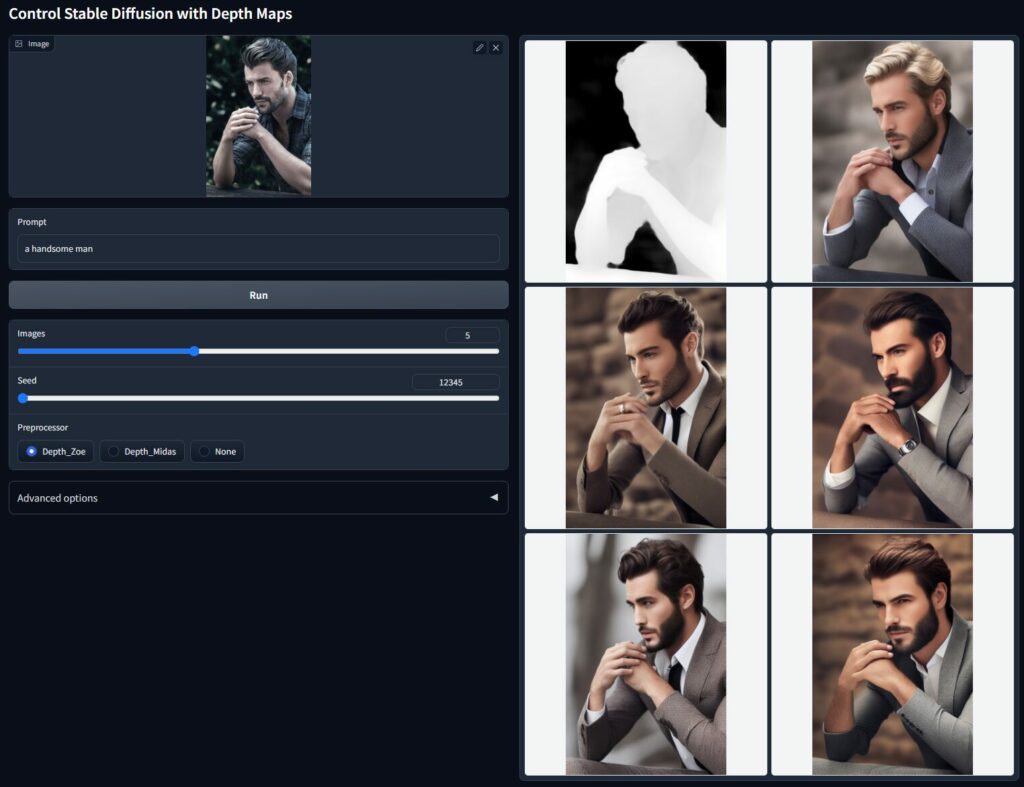
https://github.com/lllyasviel/ControlNet-v1-1-nightlyより引用
画像左側の人物をポーズを維持したまま別人に変換している様子。
(つづきは、ブログ「神戸のデータ活用塾!KDL Data Blog」へ)