KDL BLOG
データインテリジェンスチームの黒臺(くろだい)です。 様々なものを対象としてセグメンテーションができるSegment Anything Model(以降SAMと表記)を本記事ではGoogle Colaboratoryで実装をします。SAMモデルの概要について、詳しい説明はこちらの前編記事を参照して下さい。
前編のまとめ
前編の記事では、SAMのアルゴリズムはViT、CLIP、アテンション機構をベースとした応用がされていることを紹介しました。さらに、SAMモデルの学習用データに動物や風景などの画像が使用されていることも紹介しました。試しに町や建物などの画像を読み込ませると、下記の結果になります。

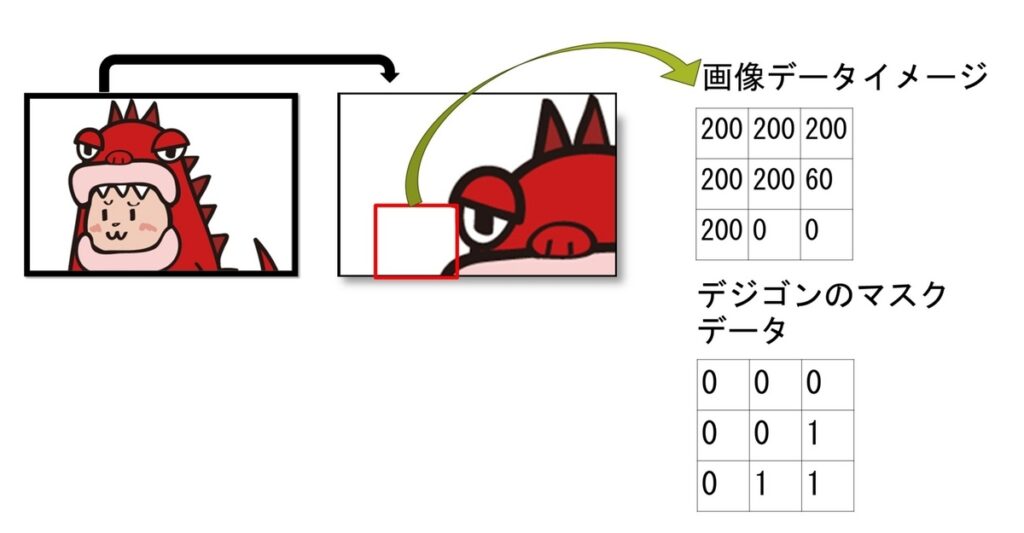
弊社の公式マスコットキャラクターの「デジごん」。学習用データにおそらく含まれていないであろうデジごんをセグメンテーションすると、どうでしょうか。結果は下記のようになりました。
セグメンテーションができていますね。
本記事では、3種類のセグメンテーション方法についてPythonを使って実装をしながら紹介をします。まず最初に、自動でセグメンテーションを行う方法について説明します。次に、プロンプトを使ってセグメンテーションを行う方法を2種類、紹介します。実装では、Google Colaboratoryを利用します。
実践編①自動でセグメンテーションを行う場合
今回は著者が撮影した画像を使います。1つの画像内に高周波成分を多く含んでいる、曲線・直線で構成された複雑な対象物が映っていることから、試験用の画像として選択しました。〈なお、1200×832ピクセルのサイズで試しました。〉

それでは、画像内の様々なものをセグメンテーションできるか実践してみましょう。
Google Colaboratory上で、画像データを読み込みします。
import cv2
# 元の画像を読み込む
original_image = cv2.imread(r'/content/kobe.jpg')
次はSAMを利用できるようにします。
#SAMと依存関係のツールをダウンロードする
!pip install -q 'git+https://github.com/facebookresearch/segment-anything.git'
!pip install -q jupyter_bbox_widget roboflow dataclasses-json supervision
#SAMの重みづけデータをダウンロードする
!mkdir -p {HOME}/weights
!wget -q https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth -P {HOME}/weights
import os
CHECKPOINT_PATH = os.path.join(HOME, "weights", "sam_vit_h_4b8939.pth")
print(CHECKPOINT_PATH, "; exist:", os.path.isfile(CHECKPOINT_PATH))
import torch
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
MODEL_TYPE = "vit_h"
#SAMモデルで利用したいモデルをインポートする
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor
sam = sam_model_registry[MODEL_TYPE](checkpoint=CHECKPOINT_PATH).to(device=DEVICE)
以上でSAMモデルをGoogle Colaboratory上で利用できるようになりました。次に画像を指定します。
import cv2
import supervision as sv
image_bgr = cv2.imread(IMAGE_NAME)
image_rgb = cv2.cvtColor(image_bgr, cv2.COLOR_BGR2RGB)
sam_result = mask_generator.generate(image_rgb)
マスク画像の結果をsam_resultの変数に格納しました。次は画像の出力方法を指定し、結果を確認します。うまくできるでしょうか?
mask_annotator = sv.MaskAnnotator(color_lookup=sv.ColorLookup.INDEX)
detections = sv.Detections.from_sam(sam_result=sam_result)
annotated_image = mask_annotator.annotate(scene=image_bgr.copy(), detections=detections)
sv.plot_images_grid(
images=[image_bgr, annotated_image],
grid_size=(1, 2),
titles=['source image', 'segmented image']
)
今回利用した画像の出力結果は以下の通りになりました。左図は入力画像、右図は出力結果です。

右図の出力結果を見たところ、ほとんどはうまくセグメンテーションができていましたが、左側の画面奥側にある建物だけはセグメンテーションすることができませんでした。

上図の白点線で囲った部分は、セグメンテーションができていないエリアを指しています。これを解消するためには、特定の物体に注力してセグメンテーションを実行する必要があります。プロンプトを使う方法が有効です。SAMモデルのプロンプトを使ったセグメンテーションは2種類あります。「ポイントプロンプト」と「ボックスプロンプト」です。ポイントプロンプトの方が使いやすいため、ポイントプロンプトを中心に紹介します。
(つづきは、ブログ「神戸のデータ活用塾!KDL Data Blog」へ)