KDL BLOG
セキュリティ事業部長の三木です。セミナーでは講師を務めることが多い私ですが、先日KDLで開催されたセミナー「サイバー攻撃に備える『DevOps』という選択」を参加者として聴講しました。その中で見えてきた様々な角度からのアプローチ方法、これから企業が取っていくセキュアなシステムの開発・運用における新しい観点に気付くことができました。
私の主観が入りますが、簡単にセミナー内容をご紹介します。
このセミナーのタイトルである「DevOps(デブオプス)」は、「開発(Development) と運用(Operations)を組み合わせたかばん語であり、開発担当者と運用担当者が連携して協力する(さらに両担当者の境目もあいまいにする)開発手法をさす」(Wikipediaより引用)と定義されるソフトウェア開発手法の一つです。
セミナーでは、厳密な定義は存在せず抽象的な概念とされがちなDevOpsについて、実践方法や実践している企業の思い、内製化の課題などを、具体例を交えて紹介されました。
もしあなたの会社にサイバー攻撃予告が届いたら
最初の登壇者はアスタリスク・リサーチ代表の岡田良太郎さん。「もしあなたの会社にサイバー攻撃予告が届いたら」という非常にキャッチ―でドキッとするテーマで講演されました。
冒頭のスライドで「DDoS」と出てきましたが、実は最近これに悩まされる企業が増えています。
- DDoS(Distributed Denial of Service)・・・・乗っ取ったアドレスに大量アクセスさせてサービスを機能停止させようとする、分散型のDos攻撃のこと

私見ですが、情報漏えい以上にシステムダウンによる業務停止が増えており、全ての企業においてリスクが高まっているように思います。セミナーでは、実際にDDoS攻撃を宣告された事例、金銭を要求された企業が支払った痕跡のある事例などが紹介されました。
データを扱わないシステムでも情報漏えい
情報漏えいの事例では、顧客のカード情報を自社に持たないシステムにも関わらず、カード情報を盗まれる手口が紹介されました。稼働環境のモニタリングが抜けているために、ハッキングが成功した事例です。通信を暗号化しデータを扱わないシステムでも、プログラムそのものが狙われて情報漏えいに至った事実に、参加者も驚いた様子で聴講されていました。
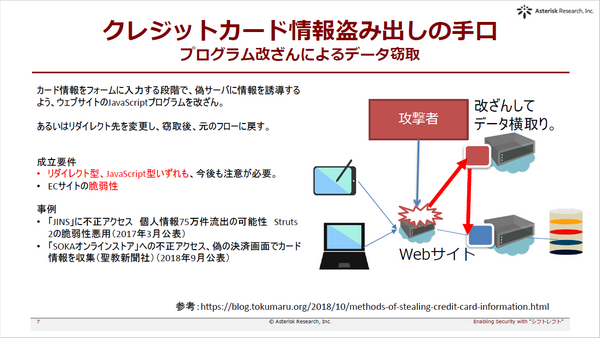
サイバー攻撃が「発見(対応ではなく)」されるまでの時間は、日本が12か国中で最も遅い結果になった(2019年、ソフォス社によるレポート)という事実は、背筋が寒くなる思いです。
ソフトウェアアーキテクチャの変化がDevOpsのからくり
岡田さんは、甚大な被害が出ている3大事故箇所として、以下の3つを挙げられました。
- アップデートされないシステム放置
- メンテナンスされていないレガシー・ソースコードの問題
- クラウドプラットフォームなど、稼働環境の管理設定・監視の圧倒的不足
確かに、これらはどの企業も完全だとはいいきれないものばかり。

これらソフトウェアに起因する問題への対策として、近年を代表するソフトウエアのアーキテクチャが、APIのようなマイクロサービスの結合に変化していることに言及。各マイクロサービスが小さく独立しているため、デプロイの頻度、変更のリードタイム、復旧時間が早いと説明されました。これがDevOpsのからくりであるというのです。
DevOpsを実践するには
岡田さんは、システムの運用側であるOpsをサーキットに、Devをピットに例えて、サーキット全体=ビジネスそのものとし、クラッシュを防ぐためのサイクルであると解説されました。「DevOpsとはビジネスをストップさせないための継続的な取り組みである」うーん、分かりやすい!
危険がわかるのは開発の段階です。だからリリースより前の対策、つまりシフトレフトが必要になります。また、運用中に開発があげなくてはならないのは、運用中の状況把握と分析。Opsが主役で、Devがそれを短いサイクルでピットストップで対策をしていくというように文化を変えていく必要性を説かれました。
両者を連携させ、開発の上流は運用、運用の上流は開発とすれば、連携が自然に成り立つ(=DevOps)というのがこちらの図です。
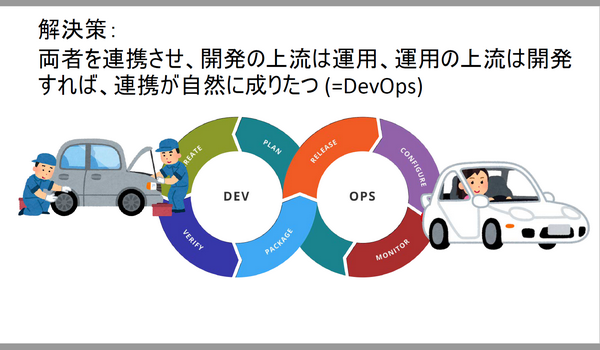
そうなんですよね。上流下流ってのが、そもそも壁を作っているわけです。
この無限ループの絵が私は大変腑に落ちました。
MSPにおけるSREの実践
次に、企業などのインフラ運用や監視、設計、クラウド導入支援などを提供するハートビーツ取締役の高村成道さんより「MSPにおけるSREの実践」をテーマにお話しいただきました。

DevOpsとSREの関係性
ポイントはGoogle社の開発・運用チームが提唱した「SRE(Site Reliability Engeneering)」です。
これは、高村さんの解釈も踏まえて言うと、「開発者とサービスレベルの目標値を共有し、協力しながら開発やテスト、本番稼働に必要なインフラ環境をすぐに使える組織横断的な仕組みを作ること」だそうです。
どのような企業でも開発と運用には溝が生まれやすく、非効率を抱えがちになるのですね。
SREのコアになる考え方は「伝統的なOps」を再定義し、その伝統的Opsをソフトウェアに任せてしまうこと。

「伝統的なOps」とは、手動に頼ったOpsのこと。例えば手動の手順書であれば、改善のたびに手順書に手順が追加される→サービスが大きくなると運用が大変になる→機能開発をしたい人と、できれば追加開発したくない人の対立になる。これを打破することがコアな考え方ということです。
ということで、SREはDevOpsとは別のところで生まれたが、結果的にはDevOpsの抽象的な哲学を具体化したものだだそうです。DevOpsとSREの対比を紹介されたのがこちら。

たしかに、よく似ていますが、左のDevOpsの考え方を手法として具体化したものがSREということがわかります。
ハートビーツ社の実践
ハートビーツさんでは、監視やモニタリングの設定作業や仕様書作成など人の手を介するものをソフトウエアエンジニアリングでツール化し、可能な限り自動化を図ったということでした。

その結果、これまで人に頼っていた箇所が次のように劇的に改善されたそうです。
- 監視項目検討、監視サーバ設定を自動生成
- 設定をコマンドで一発反映
- 仕様書作成、更新をほぼ自動生成
これは、今でいうRPAと同じエンジニアリングように感じました。現場でやろうと思えば出来るということに驚きました。何故出来なかったのか?それは、DevOpsの文化が浸透しにくかったということなのでしょう。
リリースエンジニアリングの事例
次に挙げられたのが、ハートビーツさんのお客様の事例でリリースエンジニアリングの支援です。
お客様では、デプロイ時の手間や障害、コンテンツ更新のための停止など、無駄が多く発生しているという課題があったそうです。そこで行ったのが、Biz(ビジネスサイド側)、Dev、Opsの3者合同のミーティング。これにより縦割りを無くし課題を共有、優先順位を決定し、合意を形成されたそうです。その上で、DevとOpsが協力してツールを導入し、ハートビーツさんがデプロイに関わるソフトウエアを開発した結果が以下のとおり。
- 停止メンテナンス時間が無し
- デプロイ時のメンテはオンラインで
- デプロイサイクルも一日2,3回と高速化
重要なのは文化(カルチャー)
先ほどの岡田さんの講演に続いて、高村さんも重要なのは「カルチャーである」と明言されました。MSP(マネージドサービスプロバイダ)として必要なカルチャーとして「インフラ以外見ません!」でなく、状況に応じてアプリやサイトそのものに踏み込んで、サービスの抱える課題の解決に必要な関係者を巻き込むことを重視しておられるとのことです。
 責任分界点をうたう業者が多いなか、この考えはユーザーとして非常にありがたいですね。
責任分界点をうたう業者が多いなか、この考えはユーザーとして非常にありがたいですね。
後編に続きます。↓↓