KDL BLOG
こんにちは!Dataintelligenceチームの垣内です。
前回、公開した「【PySpark】Pythonで分散処理を体験してみよう」では、簡単にPySparkの書き方をご紹介いたしました。
実務でPySparkで分散処理を実行するとなると、クラウドサービスを使うことになると思います。本連載ではAWSの分散処理サービスである「AWS Glue」を使って、分散処理を実行してみます!第一弾の今回は、AWS Glueとはなにか?そしてローカルでの開発方法や開発に使うサービス・ツールをご紹介します。
AWS Glueとは
AWS Glueは大量のデータを読み込み、加工・変換する際に用いられるサーバーレスサービスです。 ETL/ELTの構築や機械学習・深層学習でモデルを作ったり実験したいときに適しています。詳しく見ていきましょう。
AWS Glueは次の図のようなアーキテクチャとなっています。
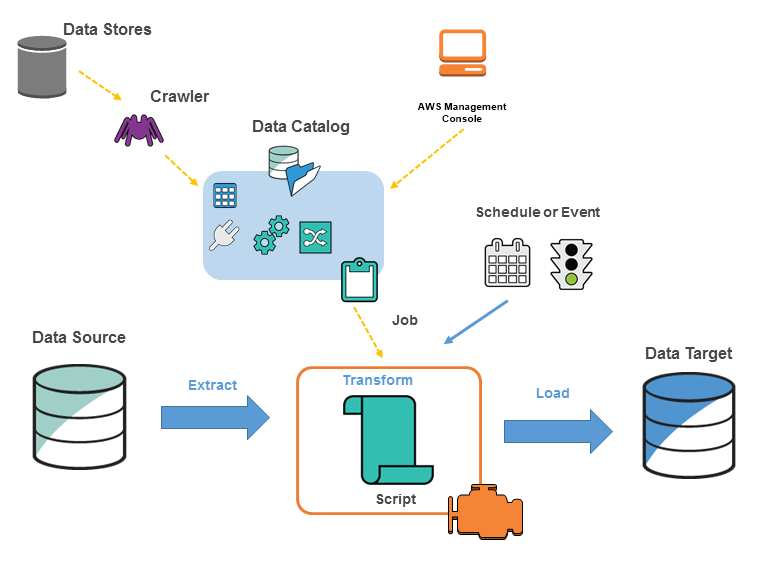
AWS Glueを構成する主な要素として「Crawler・DataCatalog・Job」があります。どのようなものか簡単にご紹介します。
| 機能 | 概要 |
|---|---|
| DataCatalog | 処理対象のデータに関するメタデータ*1を管理するデータカタログ機能 ETL ジョブの作成と監視に使われる |
| Crawler | データソースからメタデータを集め、DataCatalogに登録・更新する機能 |
| Job | ETL処理を行う機能 |
今回はETL処理を動かしたいので、Jobを使います。
(つづきは、ブログ「神戸のデータ活用塾!KDL Data Blog」へ)