KDL BLOG
KDLでは、この度「T-1グランプリ(テスト-1グランプリ)」という社内コンペティションを開催しました。初めての試みでしたが、社員、協力会社の方を含め多くの開発者に参加いただき、1か月半に渡って熱き戦いが繰り広げられました。
今回は、コンペティションの主催者の一人である生産技術チーム/PSIRTの松田が、コンペティションの様子やコンペティションをとおしてわかったことなど、ブログにまとめました。
きっかけはえらい人の一声から
みんな、テストコードって書けてんの?
松田そうですね。バラつきはあると思いますけど。
えらい人テストコードを競うコンペなんかどう。名付けてT-1グランプリ。普段当然のようにできていることに点数をつけてあげるって結構重要よ。モチベーションにもなるし。できていることって意外とわからんのよ。
松田(あれ?前にKDLで「P-1グランプリ」ってあったな。それのパクリやん)
いいですね。やりましょか。
というようなやりとりがあったのかも定かではないぐらい昔にT-1グランプリは始まりました。おそらく1年ほど前です。きっかけはささいな思いつきでしたが、テストコードを競うコンペティションという、KDLでは、未だかつてないイベントが始まりました。
“テストコードを競う”って何を競うの?
まず、初めに考えたのが、何を競うかです。テストコードを競うにあたり、明確な指標が欲しいところです。そもそもテストコードが何のためにあるかというと。一番の目的は、バグを発見することではないでしょうか。テストコードがあると、手間をかけず何度でもテストを行うことができます。機能追加した際に他の機能がバグっていないか、ライブラリにパッチを適用したときに既存の機能がバグっていないか、などを自動でチェックできます。
「よし、バグを発見できるかを競おう!!」
そんなことを考えているときに社内で別のコンペティションが開催されました。(KDL、コンペ好きやな)そのコンペに参加して感じたのは、「自動で採点される仕組みがいいな」ということです。すぐに、点数化してくれるとどれだけできているかがわかります。次のステップに行きやすく、何より公平性を感じました。「T-1グランプリも自動で採点できるようにしたい。バグの発見を自動で集計する仕組みがいいな。」
色々考えた結果、予め正常に動くブランチとバグを埋め込んだブランチを、バグのシナリオにあわせて20個ほど作っておき、参加者が作成したテストコードを、正常に動くブランチとバグを埋め込んだいくつかのブランチごとに動かして、失敗したブランチの数を集計してみました。さらに、この集計はGitHub Actionsで動かすことによって、自動で集計することにしました。
図にするとこんな感じです。
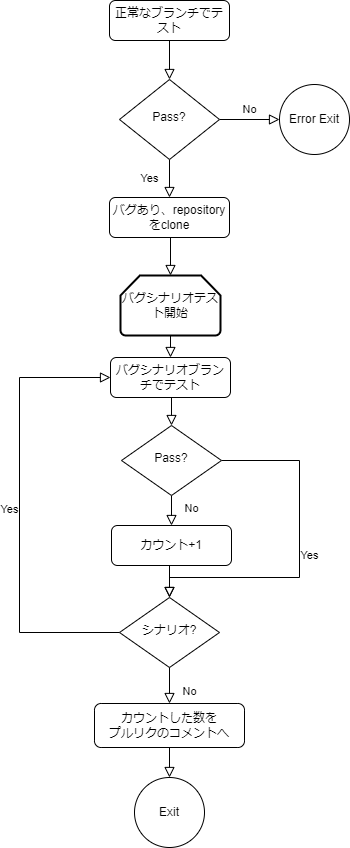
よし、これでテストコードを自動で評価する仕組みが出来上がりました。
色々な言語があります
まずは、正常に動くWebアプリケーションを準備します。今回は簡単なSNSを作成しました。
- ログインして
- 投稿すると
- 一覧に表示されます
- ユーザをクリックすると、その人の投稿に絞ります
- 自分の投稿を削除できます
これぐらいの機能ですが、色々なバグが準備できそうです。例えば、他人の投稿を削除できるとか(笑)
さらに、KDLには、色々な言語のプロジェクトがあります。お客様からのご指定であったり、開発者がチャレンジしたり。全部の言語に対応するのは難しいですが、できるだけみなさんの得意な言語でチャレンジしてほしい。そんな想いから下記の4つの部門を準備しました。
- Node.js部門
- PHP部門
- Python部門
- フロント Vue.js(E2E)部門
さらに、
- 手動エキシビション部門
を加え、計5部門としました。
Node.jsやPHP、Pythonは、バックエンドのAPIとして動作するようにし、フロントとしてVue.jsで作成したWebアプリケーションが動くようにしました。この辺りは、生成系AI、特にChatGPTなどを駆使して開発しましたので、複数の言語がありましたが、簡単に開発することができました。
ちなみに、集計するGitHub ActionsもChatGPTを使って作りましたので、生成系AI様様です。なければ、たぶんこの企画はできませんでしたね(笑)
コンペティションの開始
さて、9月某日、ついにコンペティションが開始されました。開始から多くの方に参加いただきましたが、幸い、GitHubのOrganizationに参加者ごとのリポジトリを作成し、プルリクするという、普段やっているようなフローで採点するようにしたため、大きな混乱なく、参加者が採点を始めました。
下記は、ある部門の順位と得点(バグ発見数)の推移です。
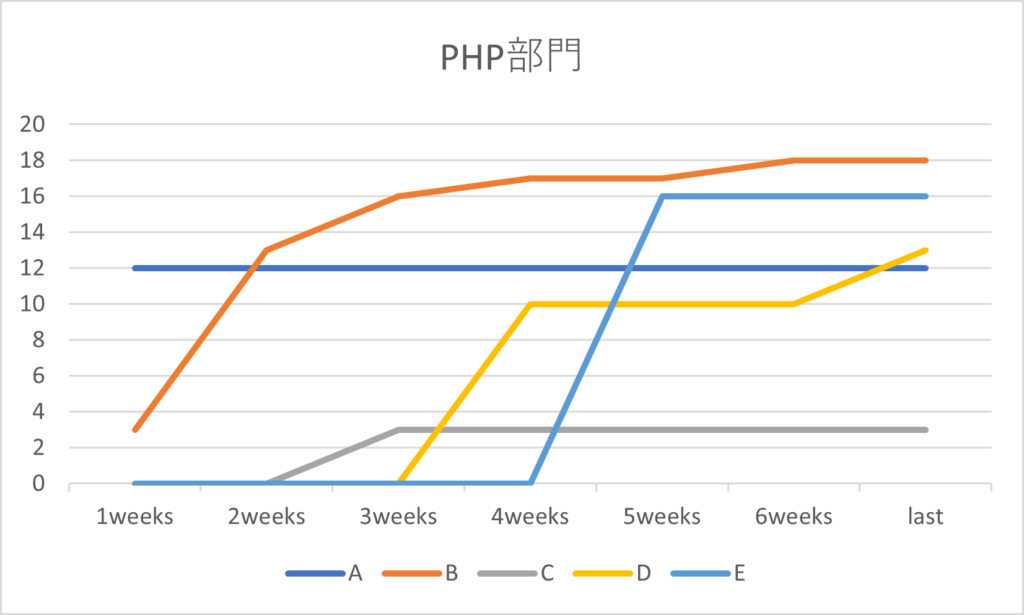
始まってすぐにコミットしている方もいます。後半に一気に点数を伸ばす方がいらっしゃいましたが、逃げ切りましたね。トップの方は、GitHub Actionsの出力からバグの検知状況を見て、どんなバグがあるか予想しながらテストコードを微調整したみたいです。
別部門の推移です。
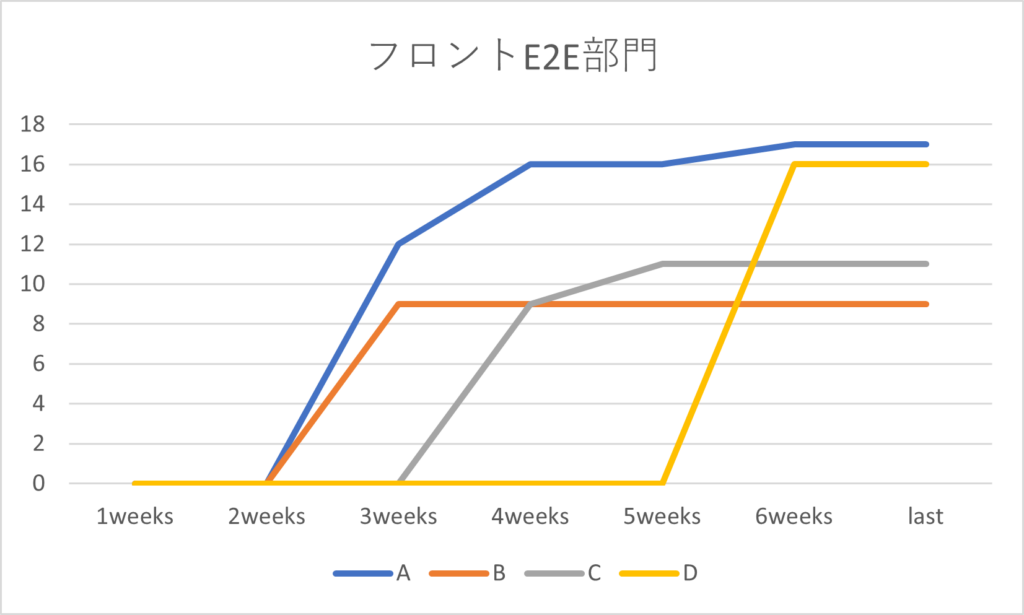
この部門は、後半にバグ発見数1つ差で2人が激しくデッドヒートを繰り広げました。最後の最後まで、採点して点数を伸ばそうとしていたのが印象的です。自動で集計する仕組みになっていたので、競争心が煽られたのかもしれません。
熱い戦いが繰り広げられ、実に87回の採点が実施され、2544分のGitHub Actionsが実行されました。GitHub Actionsは、無料アカウントの場合、2000分/月という制限があります。10月はぎりぎりその制限に達しないぐらいの時間でした。予想以上に最後はみんな動きました。
表彰式は社員総会で
多くの参加者による熱い盛り上がりを記念して(?)、なんと、社員総会で表彰式が行われることになりました。その様子は下記のとおりです。

祭の後に
ふと「みんな、どんなバグをよく見つけてるんやろ?」と思いついて、集計してみました。
今回、APIの3部門(Node.js、PHP、Python)は同じバグシナリオで、フロントのVue.js部門は別のバグシナリオを準備しましたので、サンプルの多いAPIの3部門のバグの種類別の検知率について比較してみました。
- 入力値検証に関するバグは、検知率が比較的高い。つまり、よく見つけている。
- しかし、その中でも文字種の検証に関するバグは、検知率が低くなった。
- 認証の不備に関するバグも、検知率が比較的高い。
- 認可の不備に関するバグは、認証に比べると検知率が低い。
- もっとも検知率が低いのは、ログ出力に関するバグだった。
- XSSやSQLインジェクションなど(普段は脆弱性診断で見つける脆弱性)を見つける強者がいた。
自社の傾向や改善ポイントなんかがわかって、面白い結果でした。脆弱性の早期発見にもつながりそうなので、テストコードを書く文化やそれを評価するコンペティションは今後も続けていきたいです。
Special Thanks
フロント部門開発 東田裕靖
Python部門開発 伊藤由偉
企画協力・監修 大崎努・山岡賢一・ 本間美香
企画・原案 岡田良太郎
その他、企画に協力してくれた多数の方たち
ご協力、ありがとうございました。