KDL BLOG
2024.04.17
神戸のデータ活用塾
AWSのBedrockとKendraを使ってRAGの仕組み作ってみた!~Terraform版~〔後編〕
データインテリジェンスチームの畑です。
「AWSのBedrockとKendraを使ってRAGの仕組み作ってみた!~Terraform版~」の後編です。前編の記事を未読の方は下記からご覧ください。
AWSのBedrockとKendraを使ってRAGの仕組み作ってみた!~Terraform版~〔前編〕
前編では以下のアーキテクチャをTerraformで構築するためにコードを準備しました。

後編ではRAGの仕組みを完成させます。
Lambdaの環境準備と実行コードの作成
Lambdaの処理概要
Lambdaの実行コードでは以下の処理を実装します。
- 質問文でKendraに検索をかける
- Kendraの検索結果と質問内容を元にBedrockのClaudeモデルで回答の文章を生成する
- 回答をAPI-Gatewayに返す
Lambda内のコード解説
1. 質問文でKendraに検索をかける
import json
import os
import boto3
kendra = boto3.client("kendra", region_name="us-east-1")
bedrock_runtime_client = boto3.client("bedrock-runtime", region_name="us-east-1")
def get_retrieval_result(query_text: str, index_id: str) -> list[dict[str, str]]:
"""
Kendraに質問文を投げて検索結果を取得する
Args:
query_text (str): 質問文
index_id (str): Kendra インデックス ID
Returns:
list: 検索結果のリスト
"""
# Kendra に質問文を投げて検索結果を取得
response = kendra.retrieve(
QueryText=query_text,
IndexId=index_id,
AttributeFilter={
"EqualsTo": {
"Key": "_language_code",
"Value": {"StringValue": "ja"},
},
},
)
# 検索結果から上位5つを抽出
results = response["ResultItems"][:5] if response["ResultItems"] else []
# 検索結果の中から文章とURIのみを抽出
extracted_results = []
for item in results:
content = item.get("Content")
document_uri = item.get("DocumentURI")
extracted_results.append(
{
"Content": content,
"DocumentURI": document_uri,
}
)
return extracted_resultsコードの前半部分です。
boto3.client(<リソース>, region_name=<リージョン>)
各クライアントを初期化して、リクエストを投げる準備をしています。get_retrieval_result()
Kendraに質問文を投げて検索結果を取得する自前の関数です。
引数は質問文とKendraインデックスを指定するindex_idです。index_idはデータを検索するインデックスを指定するのに使います。もしKendraの検索対象を変更したい場合は、Lambdaの環境変数から手動で変更するか、Terraformで該当のコードを変更してください。index_idはGUI上では以下に記載されています。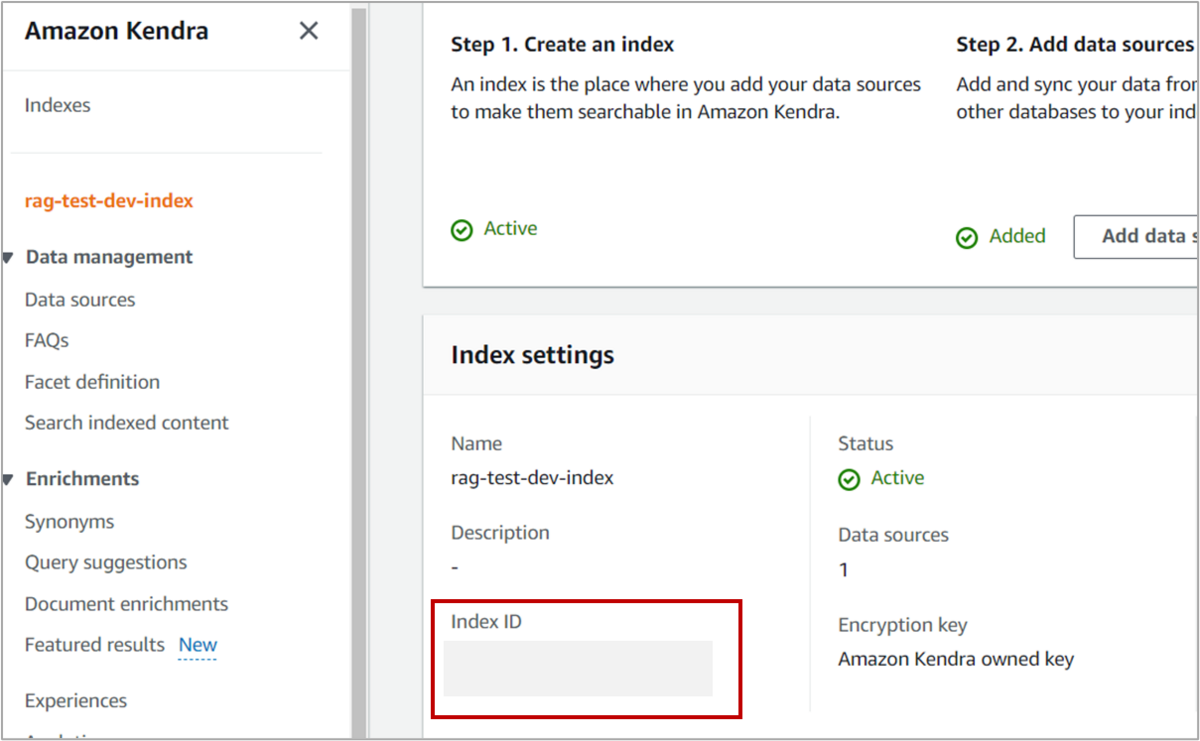
kendra.retrieve()
Kendraに検索をかけて結果を取得するAPIです。質問文で検索をかけています。詳しい書き方はこちらのドキュメントを確認してください。extracted_results
Kendraの検索結果の中から文章とURIのみを抽出します。
(つづきは、ブログ「神戸のデータ活用塾!KDL Data Blog」へ)