KDL BLOG
KDLには生成AI活用を推進するチームが2つあります。1つは、お客様へAIソリューションを提供する「Data Intelligence(以下DI)」チーム、もう1つはKDL社内のDXを推進する「KDX」チームです。
この2チームでは、技術力向上を目的として、案件や社内展開で培ったノウハウ・事例を共有し合う勉強会を開催しています。直近では「Azure AI Searchを活用したRAG(Retrieval-Augmented Generation)の文書検索精度向上」を主テーマとしたナレッジ共有を実施しました。
本記事では、勉強会で取り上げた検索精度向上の技術のうち、「セマンティックハイブリッド検索」と「アナライザー」の2つにフォーカスしてご紹介します。
RAGは、汎用的なLLM(GPTモデルなど)が回答できない社内のナレッジ等を補完するのによく使われています。
AzureでRAGを構築したけど、検索結果がイマイチ・・という方は参考にしてください。
RAGの仕組み
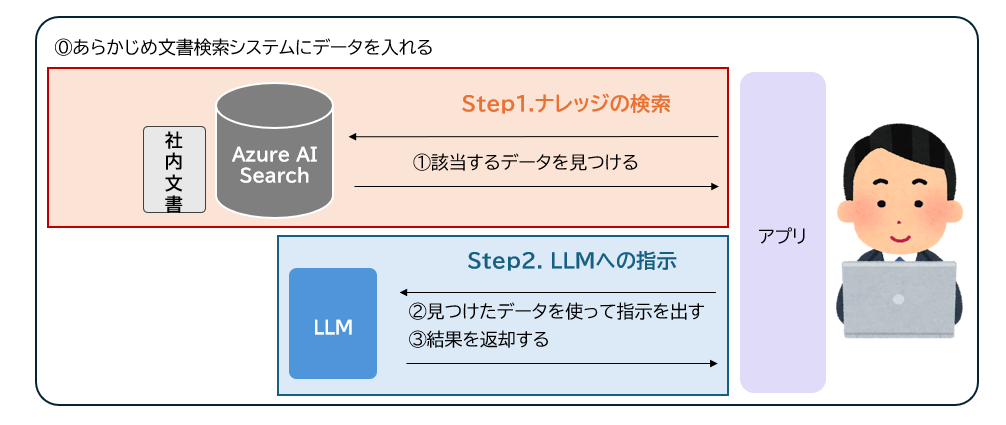
RAGは、
- Step1.
事前に準備したナレッジから検索エンジン(ここではAzure AI Search)によって該当するデータを検索する - Step2.
検索結果を基にLLMへ指示を出す
という2つのステップによってユーザーに回答(結果)を返却します。そのため、Step1.の検索精度をあげることが、RAGの検索精度の向上に直結します。
Azure AI Searchの文書検索の流れ
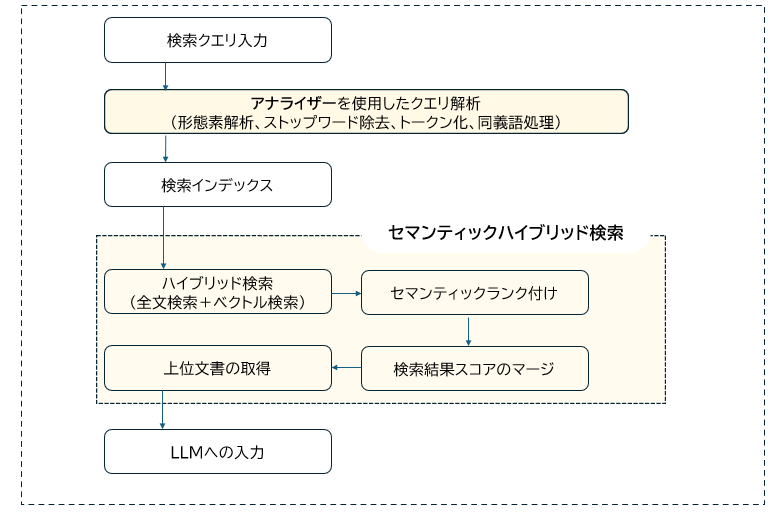
では次に、Step1.のAzure AI Searchがナレッジを検索する流れを見てみましょう。
この図の中にある「セマンティックハイブリッド検索」と「アナライザー」が検索精度向上に関わる部分です。
セマンティックハイブリッド検索とは?
Azure AI Searchの検索方法には「全文検索」「ベクトル検索」「ハイブリッド検索」「セマンティックランク付け(セマンティックランカー)」といった種類があります。これらを組み合わせた「セマンティックハイブリッド検索」は、特に検索精度が高いと言われている方法です。
2025年1月15日現在、セマンティックランカーを使ってクエリの書き換えする新機能もプレビューが公開されています。こちらはさらに高精度との報告もありますが、プレビュー版はまだサービスレベルアグリーメントなしでの提供段階のため、今回の共有会ではその前提となるセマンティックハイブリッド検索について取り上げました。
参照:Raising the bar for RAG excellence: introducing generative query rewriting and new ranking model
Azure AI検索でセマンティックランカーを使ってクエリを書き換える – Azure AI Search | Microsoft Learn
Azure AI Searchにおけるセマンティックハイブリッド検索は、2つのステップで検索結果をランキングしています。
- ハイブリッド検索(全文検索+ベクトル検索)によって、検索クエリに類似するキーワードが多い順(ハイブリッド検索のスコア順)にAzure AI Search内の文書が並ぶ。
- ハイブリッド検索で得られたスコア上位50件に対して、セマンティックランク付けが行われ、意味的に近いドキュメント順に並び替えられる。セマンティックランク付けのスコアの範囲は0.0(関連性が低い)~4.0(関連性が高い)。
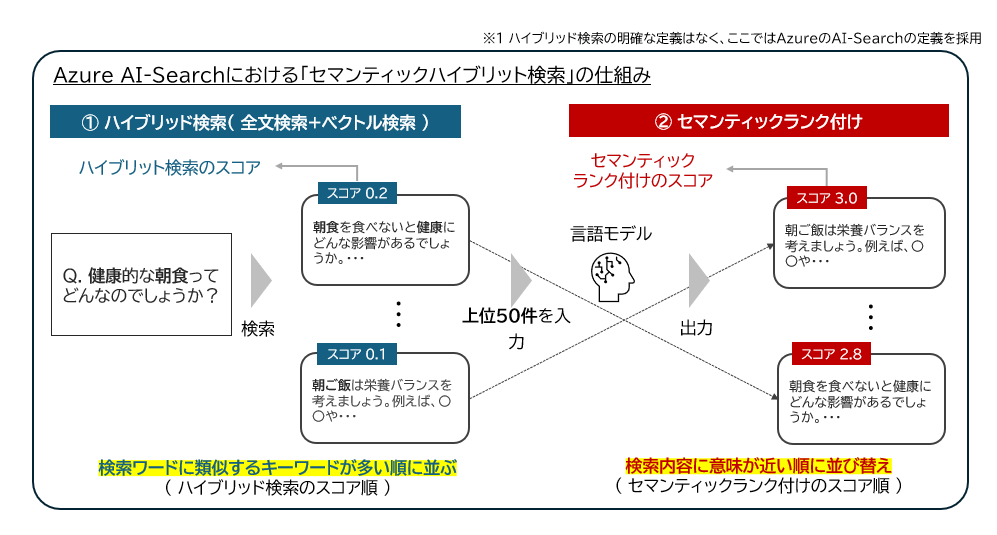
この「ハイブリッド検索のスコア」と「セマンティックランク付けのスコア」を合算して最終の検索結果ランキングを出すのがベストプラクティスであると、マイクロソフト社の公式ドキュメントでも検索スコアリング ワークフローの図の中で紹介されています。
参照:ハイブリッド検索のスコアリング (RRF) – Azure AI Search | Microsoft Learn
最終の検索結果ランキングを出すスコアの合算は、手動で実装する必要があるのがポイントです。
弊社で検証した結果、セマンティックランク付けのスコアが2.0未満のものは検索ワードとの関連性が低く、ノイズになってしまう回答結果が多かったことや、マイクロソフト社の公式ドキュメントにも「2.0以上が、ある程度関連性がある」と記述されていることから、実用段階では2.0以上を閾値として表示させています。
参照:セマンティック ランク付け – Azure AI Search | Microsoft Learn
アナライザーとは?
セマンティックハイブリッド検索のほか、Azure AI Searchの文書検索精度を向上させるために重要な役割を果たすのが「アナライザー」です。
アナライザーは、文書や検索クエリのテキストを単語レベルに分解し、意味を抽出するためのツールで、検索インデックスを作成する際や検索クエリの文字列を処理する際に使われます。
具体的には、文書内のフレーズやハイフンでつながれた単語を分割したり、重要でない単語や句読点を取り除いたり、大文字の単語を小文字に統一したりします。
検索インデックスとは、図書館の目録のようなもので、データを整理してすばやい検索を可能にするためのものです。インデックスにデータを登録しておくと、検索クエリに対して関連性の高い結果を迅速に表示することができます。
アナライザーがテキストを単語レベルに分解して標準化し、ユーザーが入力する検索クエリと、検索インデックスが適切にマッチングすることによって、検索精度が向上するというわけです。
例)ユーザーが「神戸市で働きたい」と検索した場合
・「神戸」「市」「働く」「たい」に分解
・「働きたい」を「働く」の基本形に変換
・インデックス内の単語とマッチング
アナライザーは大きく分類して「既定アナライザー」「組み込みアナライザー」「カスタムアナライザー」の3種類あります。
Azure AI Searchの「既定アナライザー」は、”Unicode テキストのセグメント化” 規則に従ってテキストを要素に分割する「Apache Lucene 標準アナライザー (標準 Lucene)」が使われています。
「組み込みアナライザー」は、特定の言語や用途に特化して事前に設計されたアナライザーです。言語に基づき設計されたアナライザーを「言語アナライザー」と呼びます。 Azure AI Searchは、35個のLucene言語アナライザーと50個のMicrosoft自然言語処理アナライザーをサポートしています。
「カスタムアナライザー」は、ユーザーが独自に設定を変更できるアナライザーで、特定のニーズや要件に合わせて設定を変更できます。
言語アナライザー
検索クエリのトークン(検索クエリを構成する最小単位)の分割方法は言語アナライザーに大きく影響されるので、検索精度を向上させるには言語(日本語)アナライザーを適用することが必須です。
例)「塩素」
・日本語アナライザー:“塩素” という単語で認識
・日本語アナライザー以外:“塩”+“素”で認識
日本語アナライザーは「Lucene」と「Microsoft」の2種類があります。どちらがいいとは一概に言えませんが、トークンの区切り方がLuceneとMicrosoftそれぞれ異なります。迷った場合、トークンがどのように区切られるかAnalyze APIで検証することができるので、試してみることをお勧めします。
Analyze APIについてはマイクロソフト公式ドキュメントを参照してください。
カスタムアナライザー
カスタムアナライザーは、特定のニーズに合わせて検索エンジンの動作をカスタマイズするためのツールです。標準アナライザーでは対応できない特殊なパターン、組織・業界固有の用語や表記ゆれを考慮した検索が理論上可能になりますが、その分パフォーマンスの検証や設定が複雑化するという特徴があります。
Azure AI Searchでは複数のアナライザーを設定することが可能です。そのため、最適なアナライザーを組み合わせて使用し、異なる種類のデータや検索ニーズに対応できます。
例えば、以下のような設定が考えられます:
- 標準アナライザーを基本として使用しつつ、特定のフィールドにはカスタムアナライザーを適用する。
- 日本語アナライザーと英語アナライザーを併用して、多言語対応の検索を実現する。
このように、複数のアナライザーを組み合わせることで、より柔軟で精度の高い検索システムを構築することができます。どのアナライザーをどのフィールドに適用するかは、具体的な検索要件やデータの特性に応じて設定することが重要です。
AI関連の技術は目まぐるしく変化していますが、KDLは一丸となって最新の技術を検証し、取り入れながら、快適なAI体験を提供してまいります。